Sustained Changes?
I have provided three new applications to accompany this month’s article. Although strictly speaking it might be more accurate to call them new versions of two earlier applications in the !Track series. One of them is a new version of !TrackGen. This works much as I explained when the original version was provided, but with one extra feature. When you run the new version of !TrackGen and tell it to create either a sinusoid or a triangle wave it asks you an extra question. This allows you to ‘dither’ the waveform or not. Dithering is recommended if you want the output waveform for a purpose like making distortion measurements. When in doubt, opt to dither the waveform. I won’t explain here in more detail as I discussed dithering in earlier articles in this series.
Click here to get a zip of the applications.
The other two applications are !TrackFFT8k and !TrackFFT32k. As you may guess, these are developed versions of the original !TrackFFT. The ‘8k’ and ‘32k’ refer to the number of CD Audio sample values (per channel) taken from the sound file you wish to examine. Here ‘8k’ means 8142 samples/channel and ‘32k’ means 32,768 samples per channel. This means the 32k version takes a chunk of sound data lasting about 0·75 seconds - sixteen times longer that the 8k version. Like !TrackFFT they just process one section of the file and output spectra for the Left and Right channel. In general, they behave like !TrackFFT, but with the following extras and improvements. Both of them now apply Triangular Window Apodisation. This generally gives better spectra for most purposes. The also carry out a THD (Total Harmonic Distortion) analysis similar to that performed by !TrackFFTScan.
!TrackFFT32k also produces an extra file of results on your ramdisc with a name starting “32kpeakaves_” followed by the name of the input sound file. This new output is useful for various reasons. Firstly, the 32k spectra have 16 times higher frequency resolution than the 8k results. This is good news if you need high resolution, but the downside is that a lot of data is required to be saved into the spectrum file (now called “32kspectrum_” followed by the input file name). The resulting text files are typically almost half a megabyte in size. Rather larger than convenient for many purposes! The !TrackFFT32k application therefore looks though the spectra in groupings of 16 adjacent frequency bands, and finds the average and peak power in each group of 16. It then saves these peak and average powers into the new file. The result is more convenient if you just wish to do something like use !Tau to produce DrawFiles to show the overall shapes of the spectra. These results are also very handy if you want to assess peak and average values... which leads me to the main point of this article!
Let’s look again at the task I was tackling last month. The problem is to decide when a spectral component is ‘noise’, and when it is ‘signal’. The aim being to remove the noise and get a result with an improved signal/noise ratio.
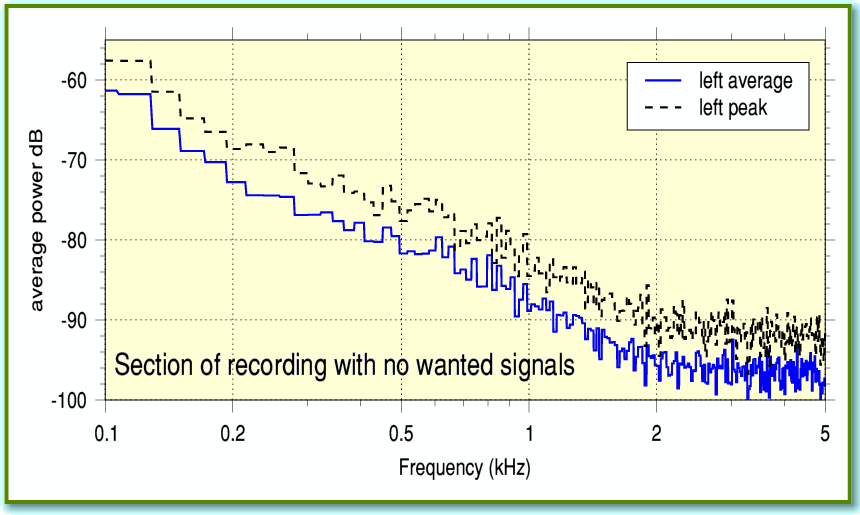
Figure 1
Figure 1 shows the peakave spectrum of a section of the recording I’m using as an example. During this section no-one is speaking, so the spectrum consists only of the (unwanted) background noise. For the sake of clarity I will just look at one channel of the stereo recording. The broken line shows the peak level for each group of 16 components. In effect this shows the level which the noise only reaches about 1/16th of the time.
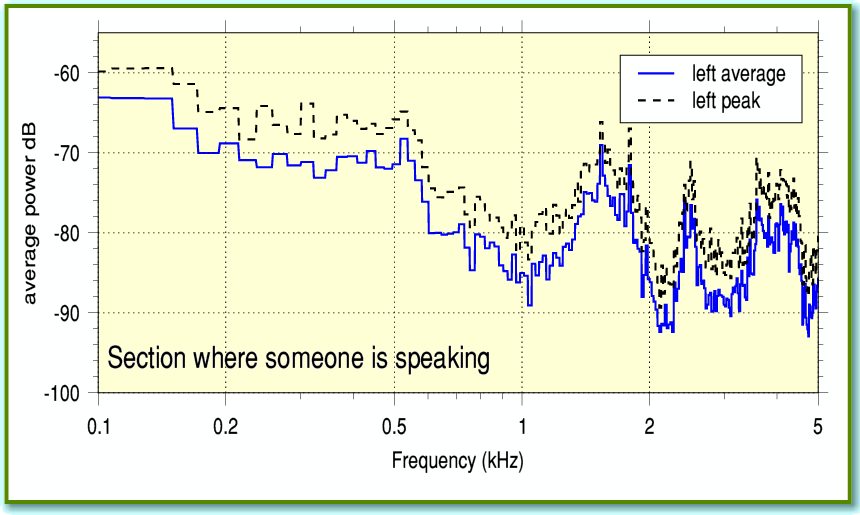
Figure 2
Figure 2 shows the spectrum from another part of the recording. This time someone was speaking. As before, the broken line is the peak level, and the solid line is the average. We can now put together these results as shown in Figure 3.
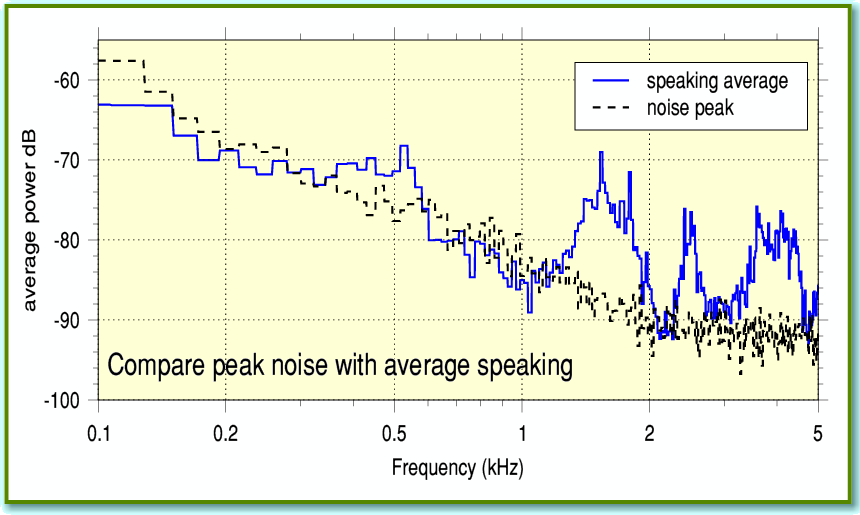
Figure 3
This compares the peak during the noise-ony section with the average during the speaking section. If we used this peak noise level as a sort of ‘template’ we could remove about 15/16th of the unwanted noise power, and reduce the audible noise level by around 12dB. This would be a useful improvement, although not a massive one. The cost is the risk that some of the speaking information would also be stripped from the results, altering the sound of the voice.
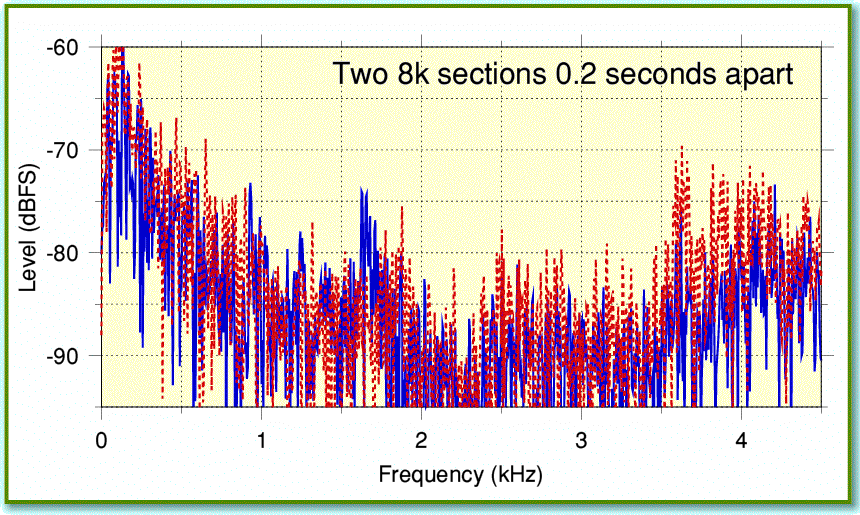
For Figures 1-3 I used the new !TrackFFT32k application rather than the 8k version. However to illustrate another of the problems we face, lets go back to looking at 8k sections of the sound data. In Figure 4 I have plotted part of the spectra for two 8k sections of the speaking part of the recording, just a fifth of a second apart. Although it may require the editor to put the result onto a colour page to be clearly visible, the results show that the spectrum varies with time.
Of course, this result is hardly surprising, but it does have some quite important implications when we are trying to process the recording to remove noise. If the signal had been constant – e.g. a sinusoidal tone at a steady frequency – then we could have exploited this by using very long durations for our FFTs and produced a large number of frequency components in the spectra. A long duration FFTs narrows down the widths of the bands in the spectra. This would allow us to remove more noise than if we used a shorter duration FFT. However this only works if the signal is ‘stationary’ during the duration of our FFT – i.e. that its statistical properties and its spectrum stay the same throughout. If the wanted signal frequencies and levels vary a lot during the portion of the recording being transformed, then we don’t get the same benefit. Indeed, if the wanted signal varies a lot, its energy is spread out, and will be more easily confused with noise. So there will tend to be an ‘optimum’ duration for the choice of FFT that gives the best ability to remove noise without also killing too much of the wanted signals. Alas, this optimum will depend on the details of the signal patterns we are wanting to preserve! So I can’t give a general rule that will always work. The choice ends up being one based on analysis of the types of sounds we happen to be trying to rescue from being buried by noise! I hope to say more about that in a later article.