This page provides a version of the content of an article published in Hi Fi News in April 2004.
Two recent developments in audio – supertweeters, and upsampling digital to analog convertors – are controversial because is isn’t very clear how they can have an audible effect. Of course, controversies like this aren’t exactly new. For decades people have argued over why some people prefer valve amplifiers to transitor designs, or if LP ‘sounds better’ than CD.
OK, maybe the differences some people say they can hear aren’t really there. Perhaps they are just imagining things. On the other hand, perhaps at least some of these differences are real. But if so, how can we explain them? There seems to be a clash between what might be called the ‘conventional’ view of what is required for a good audio system, and what some people actually prefer. Might the reason for this discrepancy be that human hearing is stranger than people in the Hi-Fi field assume? Is it possible that some things which we tend to assume are ‘inaudible’ may actually be heard? Might the ‘technical imperfections’ of vinyl LP, and low feedback valve amplifiers change the sound in ways that alter our ability to hear and enjoy the music? To seek answers to questions like these, it’s worth looking at recent advances in the understanding of human hearing. The results of doing this are perhaps surprising,...
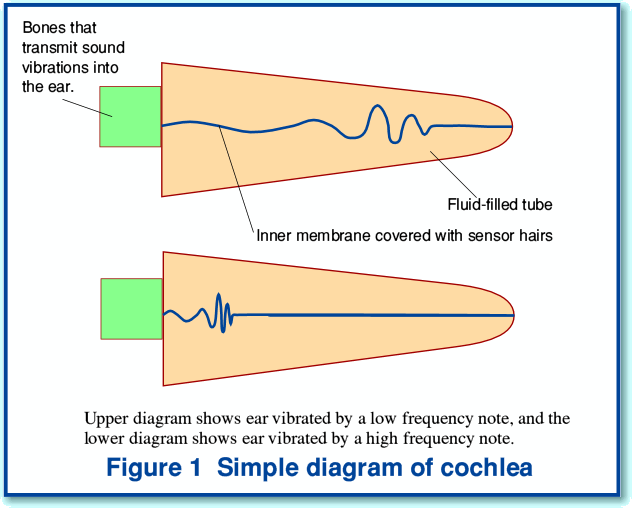
Figure 1 shows a simplified diagram of the physical arrangement in our ears. It consists of a set of basic parts. The soundwaves enter the ear, strike the eardrum (a thin sheet which covers the inner parts of the ear) and set this vibrating. These vibrations are then linked to the inner sections of the ear by a set of tiny bones which act as a sort of mechanical transformer. The output from these bones vibrates an inner structure which essentially consists of a tapered tube. In reality, this tube is wound up into a spiral, but for the sake of clarity I have shown it staightened out in the diagram.
Along the length of the tube, there is a thin membrane which divides it in two. Each part of the tube is filled with fluid. On the membrane’s surface there are a large number of tiny bundles of hairs. These hair bundles are the sensors that convert vibrations into nerve signals which are then sent off into the brain. Sound vibrations shake the membrane, wiggle the hairs, and provoke a series of nerve impulses. We then ‘hear’ music, speech, etc, when our brain receives and analyses the resulting sets of nerve impulses from this array of sensor hairs.
The traditional understanding of how the membrane and hair bundles work is similar to a harp. The hairs vary in size along the membrane. At one end of the tube, the hairs are large, and hence tend to resonate at low frequencies, just like the longer, heavier strings on a harp. As we move along the membrane, the hairs vary, and hence respond to different frequencies. Hence we can ‘hear’ which frequencies (tones) are present in the soundwave when our brain detects nerve signals from some hairs, and not others. The ability to discriminate one frequency from another is enhanced by the tendency for high frequencies to only penetrate along the membrane for a relatively short distance before being absorbed. Thus low frequencies will tend to penetrate deep into the ear, but high frequencies only shake the parts near the entrance. The higher the frequency, the shorter the portion of the inner ear membrane which will tend to be vibrated by a sound.
The diagram in Figure 1, and the description I have just given is a simplified version of the traditional view and I have omitted a number of details. However, it’s my impression that most people in the audio field tend to assume that hearing works pretty much as I have just described it. The snag is that there is now a considerable amount of experimental evidence that tends to show that the above description of how we hear fails to explain a number of things which people have discovered about the behaviour of human hearing. Here I can briefly mention just three examples:
Beat tones
The astonishing range of sound intensity levels we can hear
Acoustic emission from the ears (otoacoustic emission)
Beat tones are a well-established phenomenon which has been exploited by people like the builders of church organs. By playing notes at two chosen frequencies, the effect causes the listener to hear a note at a quite different frequency. This allows an organ builder to create the sound of very low notes without actually having any long pipes tuned to the frequency of the percieved result. The curious thing about this phenomenon is that the actual sound wave in the air carries no vibrations at the pitch which the listener hears! The implication is that the human ear has some non-linearity which ‘mixes’ the tones that are present to create the perception of a note which isn’t actually being played.
The loudest sounds humans can bear to hear are around a million million times (120 decibels) more powerful than the quietest sounds we can just detect. In a simple linear system, the amplitude of vibrations produced by sound should be proportional to the square root of the power level. Increasing the power level a hundred-fold (20 dB) should cause vibrations which are ten times greater. Hence we can expect that changing the sound power or intensity by a factor of 120 dB will cause the size of any resulting vibrations to change by a factor of a million. However, if we assume this rule applies to hearing we encounter a puzzle.
Let’s assume that the faintest sound we can hear is one that causes a vibration in our ears which moves the sensing hairs back and forth by just one micron (a millionth of a metre). Increasing the sound level by 120 dB should then cause the same hairs to vibrate back and forth by a metre! Clearly, this can’t be correct as it would mean our ears leaping out of our heads! On the other hand, if we assume that the very loud sound moves the sensor hairs in our ears by a more modest amount – say, just 1 millimetre – then it would seem that the softest audible sounds should move them by just one nano-metre (a thousand millionth of a metre) – i.e. about ten times the size of a typical atom. This is such a small movement that it seems suprising that we could detect it. The range of sizes of movement, from the loudest to the quietest sounds, is so great that it seems hard to believe our ears could function over this entire range. Yet people can hear over a 120 dB range of sound levels.
It turns out that we can solve this riddle by changing one simple assumption we made earlier. To see what this is, lets now consider the third, and most remarkable, example I listed above, namely “otoacoustic emission’’. This phrase refers to the ability of our ears to produce sound. We tend to think of our ears as passive systems, like microphones. However a few decades ago it was discovered that our hears can emit sounds, not just detect them! Physiologists can now place microphones and movement sensors in the ear and pick up vibrations generated in the ear itself! Vibrations like this are often associated with hearing damage, or ageing.
Recent studies of the ears have led to a modern understanding where hearing is physically active. The sensing hair bundles in our ears are linked to small stumulators. These tend to try and physically push the hairs into oscillatory vibrations. In normal circumstances, the push they apply should be too weak to produce any discernable vibration. However the level of this physical stimulus is affected by the movement of the hairs themselves. As a result, the sensor system is an active one, with local feedback. When working correctly, each sensor (hair bundle) is just on the edge of bursting into spontaneous oscillations. This internal ‘push’ makes it much easier for faint sounds to actually move the hairs as the incoming sound is being assisted by the push. In electronics, behaviour of this kind is familiar to engineers as a form of positive feedback. Indeed, some early radio receivers made use of this technique to obtain very high amplification gains from just a single valve. The drawback being a tendency to burst into unwanted oscillations when things get out of hand.
The sensitivity of the hairs to external sound will depend upon how much extra ‘push’ the stimulators in the ear are applying. Experiments carried out during the last couple of decades show that the ear quickly adjusts the amount of ‘push’ it applies to each hair bundle, depending upon the sound level. When the sound level is low, the ‘push’ is strong, and the sensitivity is high. Hence at low sound intensity levels, we only require a tiny sound input to make the sensor hairs move because they are being helped along by the internal stimulation. However, when we apply a higher sound level, the ear reacts by lowering the amount of ‘push’ provided by the internal stimulators. As a result. the system has a variable gain built into it response. This quickly adjusts the sensitivity to adapt to the sound level.
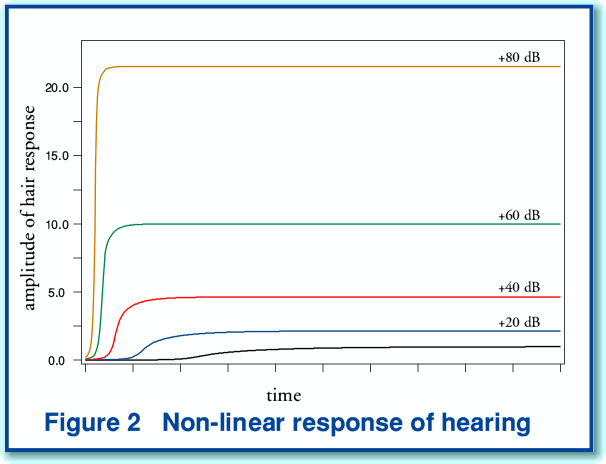
When our ears are damaged, or sometimes when we are unwell, the gain can become too high and will cause unwanted oscillations (“ringing in the ears”). However in normal situations it means that the size of the sensor vibrations does not grow as quickly as we’d expect as we increase the sound level. Hence our ears can cope with enormous variations in sound power level, yet the amplitude of the sensor vibrations only changes by a much smaller amount. Measurements carried out by researchers have recently shown that the amplitude of the vibrations of the hair bundles tuned to any particular frequency only rises with the cube-root of the size of the vibrational force applied by the sound entering the ear. As a result, an increase of, say, 60 dB (a million-fold change) in the sound level only causes the size of the movement of the hair bundle in the ear to increase by a factor of 10! The result is that our ears can easily cope with a huge range of sound levels.
Figure 2, above, illustrates in general terms the response of the hair sensors to a tone-burst as a function of time for a set of sound intensity levels. The tone-burst commences at the origin on the left. The power levels are in 20 dB steps, starting with an arbitrary 0 dB level. The vertical axis shows the amplitude of the vibration of the hairs at any time. The graph is just based upon a simple mathematical model of how the hairs respond, but shows the two most obvious non-linear properties. Firstly, that amplitude of the response only grows quite slowly with the sound level, and that a 60 dB increase only makes the vibration ten times larger. Secondly, that the time the hairs take to fully respond falls as the sound level increases. In effect, the sensors react much more quickly to loud sounds than to quiet ones.
The above results are remarkable enough in themselves. However, perhaps even more remarkable is that the same theories used to explain the above aspects of hearing also indicate that our hearing is inherently non-linear – even at low sound power levels. For example, current research work indicates that if a particular sensor will resonate to a frequency, , then it may also respond when we apply a pair of frequencies, and , provided that they are chosen to have values so that .
This may have some interesting implications for the way we hear music, and why some people may prefer hi-fi systems which at first sight seems to be flawed. At this point I need to plant a flag to make plain that what I have written about hearing up until now is reasonably well established by scientific experiments and measurements upon hearing. Much of what follows is speculation, based upon wondering what implications the current non-linear model of hearing might have for listening to music - particularly via an ‘imperfect’ audio system.
Lets start with ‘supertweeters’ and the ‘ultrasonic’ output of audio systems. The conventional view – based largely upon hearing measurements with sinewave test tones – is that a typical person with good hearing will be able to hear up to around 20 kHz. The precise value does vary from person to person, but 20 kHz tends to be the generally accepted value for what is typical. On this basis, it should be impossible for the presence or absence of signals well above 20 kHz to have any audible effect. Yet some people say they can hear a difference when such ‘inaudible’ components are added to or removed from a sound pattern.
Speculation 1: Might this effect be due to a non-linear mixing of the ultrasonic components with those well below 20 kHz? i.e. could it be that when ultrasonic components accompany an audible tone, they affect the perception in some way?
Most of the measurements to determine the range of frequencies which human beings can hear have used sinewave test signals, where only one frequency at a time was present. These would not reveal any effects which required non-linear mixing or ‘beat’ effects. Some experiments have been carried out where two ultrasonic tones, and were played to see if the listener could then hear the difference tone, . For example, by playing 30kHz and 30·5kHz symultaneously and seeing if people could then ‘hear’ a tone at 500 Hz. In general, these experiments failed to show any positive results. However this may not totally exclude ultrasonic audibility for two reasons.
Firstly, the models of human hearing sensors seem to imply sensitivity to higher order mixing – for example to . In the above example this would mean having to hear 2 ´ 30 kHz - 30·5 kHz = 29·5 kHz – i.e. also ultrasonic. Hence the actual mixing tones which the sensor non-linearity may induce to might, in many tests, also have been ultrasonic rather than being at a normally audible frequency.
Secondly, the membrane/fluid system along which the sound waves pass to excite the hair bundles is, in itself, non-linear and dispersive. Its properties vary along the length of the ear, and are activily modified by the behaviour of the hair sensors. High frequency signals normally only penetrate a very short distance along the membrane, and hence are generally assumed to not even be able to reach the sensors that might react to a lower frequency. However non-linear dispersive/active transmission systems can have some very strange properties. It may therefore be that that the presence of a lower frequency might enhance the ability of the system to carry some quite specific, higher frequencies. Thus, in principle at least, it may be that normally ‘ultrasonic’ components might be able to penetrate the ear more effectively if they are accompanied by an ‘audible’ lower note with which they have a suitable relationship. This might perhaps mean that normally ultrasonic tones could have an audible effect – but only when accompanied by a lower frequency which is already audible.
Testing the above speculation would be quite difficult as it requires experiments to see if people’s reactions to audible tones are affected by ‘ultrasonic’ components that are related to them in some complex way. Simple, “Can you hear anything?”, tests would not suffice. We would also have to be very wary of distortion effects in the test equipment masking or mimicking any results. If any effect like this does occur it may be very subtle, and perhaps not everyone would respond or be able to notice. However, if such effects do occur, they might explain why some people say they can hear the effects of super-tweeters, or are sensitive to the affects of filtering at ‘ultrasonic’ frequencies.
OK, now on to Speculation 2: Might the non-linearity of human hearing be exploited by those audio systems which create significant levels of low-order distortion to produce results which some people find actually enhances their ability to perceive and enjoy music?
A number of people say they prefer the sound of low-feedback valve amplifiers and/or Vinyl LP to low-distortion transistor amplifiers or CDs. A distinguishing feature of both low-feedback amplifiers and the LP replay system tends to be a relatively high amount of low-harmonic distortion whose level tends to increase with the sound level. This seems in some cases to cause people to argue that the result is “more dynamic” in some way. Yet such systems, when examined using tradiational engineering measures, have a lower dynamic range than something like a CD player.
Could it be that sometimes the distortions introduced by old Valve amp designs or Vinyl LP alter perception and ‘enhance’ the ability to hear? For example, when a note starts or stops suddenly it takes a short while for the sensors in our ears to react and adjust their gain/sensitivity level. Given their inherent non-linearity, this might mean that the presence of some distortion might alter the initial response to an abrupt change in sound level, making it more noticable. Similarly, the change in distortion levels with sound intensity might also affect the gain/sensitivity behaviour of the sensors, altering the percived relative loudness. The result might be a perceived increase in the dynamic changes.
At present it is quite hard to know if the above speculations have any validity at all. I should say that I am personally quite doubtful that they are correct. My personal preference tends to be for Hi-Fi systems which have minimal distortion and which reproduce sounds as accurately as possible. Despite this, it is clear that many people do prefer the results of using systems which can be expected to alter the sound. Whatever the science and engineering involved, the primary purpose of domestic Hi-Fi equipment is to allow people to enjoy listening to music and speech. A fuller understanding of hearing may help us to make even better-sounding audio equipment, and so enhance the pleasure. So for various effects like those I have described, the intriguing question remains, “Can you hear this?”
J. C. G. Lesurf
Original written: 24th Nov 2002
References:
1. The Power of Hearing. T. Duke.
Physics World May 2002 pages 29-33
2. Mechanics of the Mammalian Cochlea. L. Robles & M. A. Ruggero
Physiological Reviews July 2001 (Vol 31) pages 1305-52
3. Essential Nonlinearities in Hearing V. M. Egufluz et. al.
Physical Review Letters 29 May 2000 (Vol 84 Number 22) pages 5232-5